


Standardized usability questionnaires: post-task measures
Part 2: post-task questionnaires


A standardized questionnaire is a questionnaire that is written and administered so all participants are asked precisely the same questions in an identical format and responses recorded and scored in a specific, consistent manner (Boynton et al., 2004).
There are two categories of questionnaires used during usability testing:
Post-task questionnaires: These measures are completed immediately after users finish a task and they capture their impressions of that task (e.g., Overall, this task was…?). A question is usually presented after the end of each task, which results in multiple answers collected within a session.
Post-test (post-study) questionnaires: They are administered at the end of a session (or can be used after a user has interacted with a product). They measure the user’s overall impressions of an app or a website.
The first part of this series was focused on post-test questionnaires. The focus of this article will be post-task questionnaires.
Post-study questionnaires are important instruments in the usability practitioner’s toolbox, but they assess satisfaction at a relatively high level and provide limited insight when we are trying to find problem areas in a user interface. Post-task questionnaires can help with this as they allow us to perform a quick assessment of perceived usability immediately after users complete each task or scenario in a usability study. Usually, post-task questionnaires have a positive correlation with post-study measures but they are not identical. As a result, it makes sense to take both types of measurements when conducting studies as they can both contribute to our understanding of the user experience.
According to Saura and Lewis (2012), the most commonly used post-task questionnaires are listed below:
After-Scenario Questionnaire (ASQ) (Lewis, 1991)
Subjective Mental Effort Question (SMEQ) (Zijlstra & van Doorn, 1985; Sauro and Dumas, 2009)
Expectation ratings (ER) (Albert and Dixon, 2003)
Usability Magnitude Estimation (UME) (McGee, 2003)
Single Ease Question (SEQ) (Sauro & Dumas, 2009; Tedesco & Tullis, 2006)
ASQ
The ASQ is a three-item questionnaire measuring overall ease of task completion, satisfaction with completion time, and satisfaction with support information. The overall ASQ score is calculated by the average of the responses to those three items. The ASQ has high reliability, sensitivity, and concurrent validity (it correlates significantly with task measures of usability such as success rate).

SMEQ
The SMEQ (also known as the Rating Scale for Mental Effort, or RSME) was developed by Zijlstra and van Doorn in 1985.
It is a single-item questionnaire with a rating scale from 0 to 150 with nine verbal labels ranging from “Not at all hard to do” ( just above 0) to “Tremendously hard to do” ( just above 110). The original version was paper-based and participants had to draw a line through the scale to indicate the perceived mental effort it took to complete a task. The SMEQ score is the number of millimeters the participant marked above the baseline of 0. An online version was developed by Sauro and Dumas (2009) in which participants use a slider control to indicate their ratings. Research suggests that the SMEQ has good reliability and concurrent validity.

ER
Expectation ratings measure the difference between how easy a task was experienced to be and perceived to be beforehand by the user. The expectation rating procedure gets participants to rate the expected difficulty of all of the tasks planned for a usability study before doing any of the tasks (the expectation ratings), which are then compared to ratings collected after the completion of each task (the experience rating).
Expectation rating question: “How difficult or easy do you expect this task to be?”
Experience rating question: “How difficult or easy did you find this task to be?”
Users have to respond using a 5 or a 7-point Likert scale (from Very Easy to Very Difficult). For each task, the average expectation rating and the average experience rating can be visualized as a scatterplot. Results can be mapped onto four quadrants suggesting which features need to be improved and prioritizing the work. In particular:
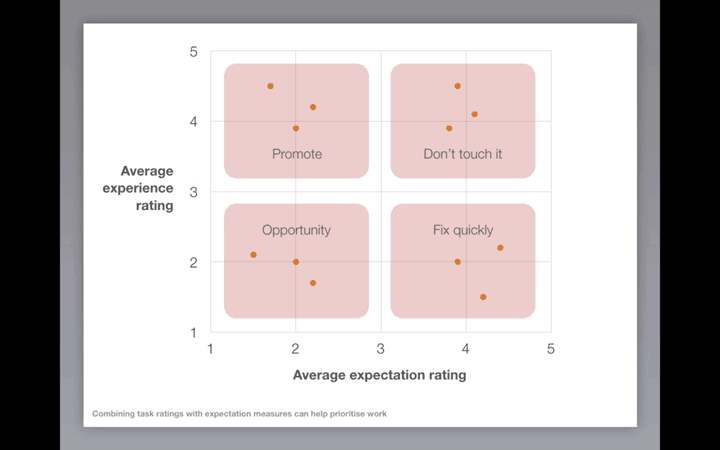{kind=link}
In the upper left quadrant are the tasks that users thought would be difficult and actually were easy (“Promote it”). These are features that may help distinguish the tested product from the competition and should be promoted as such.
In the lower left quadrant are the tasks that the users thought would be difficult and actually were difficult (“Big opportunity”). There are no big surprises here, but there could be important opportunities to make improvements.
In the upper right quadrant are the tasks that the users thought would be easy and actually were easy (“Don’t touch it”). As the name suggests no changes are needed for these features as they are working just fine.
In the lower right quadrant are the tasks that the users thought would be easy but actually turned out to be difficult — a potential source of user dissatisfaction (“Fix it fast”). These are the tasks that should be the primary focus for improvement.
The ER is reliable and has good concurrent validity and sensitivity (Tedesco & Tullis, 2006).
UME
Magnitude estimation has a rich history in psychophysics, the branch of psychology that attempts to develop mathematical relationships between the physical dimensions of a stimulus and its perception. It was created to overcome some of the disadvantages of Likert scales, such as ceiling and floor effects). Users are asked to create their own scale (from 0 to no limit/subjective limit. The goal of UME is to get a measurement of usability that enables ratio measurement, so a task (or product) with a perceived difficulty of 20 is perceived as twice as difficult as a task (or product) with a perceived difficulty of 10. Calculating the results can be quite complex as the resulting ratings need to be converted into a ratio scale of the subjective dimension (Sauro & Dumas, 2009; McGee, 2003).
The UME has high construct validity, is sensitive, and is easy to interpret. However, practitioners often avoid using it due to the complexity of the scoring process.
SEQ
The SEQ simply asks participants to assess the overall ease of completing a task using a 5- or a 7-point scale. This is the most commonly used rating scale in usability testing. Even though it is simple, the SEQ has high concurrent validity and reliability (Sauro & Dumas, 2009).

Which one to use?
The psychometric data support the use of all five post-task questionnaires: ASQ, SEQ, SMEQ, ER, and UME. They all have good scores when it comes to validity and reliability. If using below 10 participants, none of the above questionnaires have high detection rates. As a result, a sample of at least 10 users should be used to produce meaningful results.
Research has shown that the SMEQ correlates significantly with other post-task measures such as the SEQ and the SMEQ. It also correlates with post-study measures like SUS scores and completion time, completion rates, and errors.
Recent studies of post-task questionnaires generally support the use of single items, and the two best of those are the SEQ and the SMEQ. If you are after simplicity, the SEQ is the simplest measure of post-task usability and has sufficient psychometric. It is best used with 7 rather than 5 scale steps to increase its reliability of measurement (Sauro and Dumas, 2009). In general, the more scale steps (e.g., 5 or 7 choices) in a questionnaire item the better. An alternative, suitable for online questionnaires, is the SMEQ, which is slightly more sensitive than the SEQ.
It is important to note that self-report measurements of usability are not a substitute, only a complement to other performance measures and qualitative testing methods.